Machine learning is very popular nowadays. Everybody claims that they are doing it 🙂 This tutorial will try to explain a few terms in the field of machine learning and use an example to learn the data and make a prediction based on the model derived from the data. We will use C# in this tutorial.
The data is a spreadsheet (download here ) that contains a few thousands records of Gender, Height and Weight, like this:
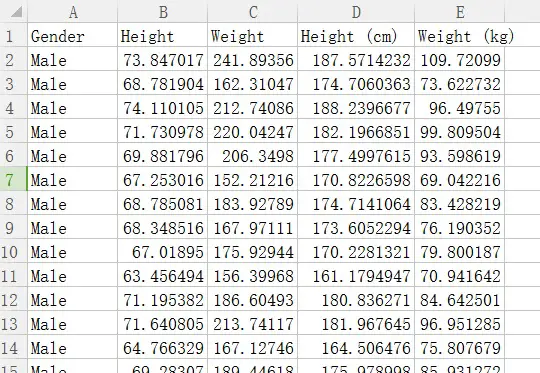
data-training-set
We can then divide this data into two, the training set and the verification set. The training set is used to train the model via the machine learning algorithm and the verification is used to see how good the prediction model is.
If the model is tuned too much, we will have a ‘overfit’ model that only works for a particular input (e.g. training set) but may perform badly for other data sets. If we do not consider enough parameters/factors, the model may fail to make an accurate prediction in most cases (model underfit).
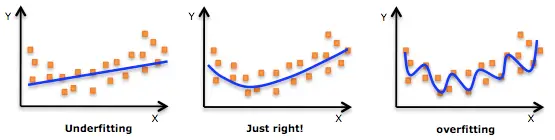
overfit and underfit
We may need to remove the invalid data from the data-sets because such data is considered as ‘noise’ or they are an exceptional case.
Error
We can measure how good the model is by computing the Root-Mean-Square-Error, which mathematically is defined as:
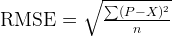
where P is the prediction data and X is the verification data, and n is the number of prediction samples. Less RMSE, better the prediction model is. We can compute the RMSE by the following C# code:
// helloacm.com
static double RMSE(IList<double> pred, IList<double> y)
{
if (pred == null || y == null)
{
throw new ArgumentNullException();
}
if (pred.Count != y.Count)
{
throw new Exception("pred.Count != y.Count");
}
if (pred.Count < 1)
{
throw new Exception("pred.Count < 1");
}
var result = 0.0;
for (var i = 0; i < pred.Count; i ++)
{
result += (pred[i] - y[i]) * (pred[i] - y[i]);
}
return Math.Sqrt(result/pred.Count);
}
One Single Model for Human
If we don’t take gender into consideration, we can have a single model that only has 1 parameter, which is height. If Height is X, Weight is Y then:
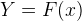
where the F function is the prediction model.
Preparing the data
First, define and enum type that specifies the gender.
// helloacm.com
private enum Gender
{
Male,
Female
};
Now, we need to Read the csv spread sheet and parse the data into List of doubles.
// helloacm.com
private static void ReadData(string filename, IList<Gender> gender, IList<double> weight, IList<double> height, int offset, int step)
{
var raw_string = File.ReadAllText(filename).Split(new[] { "\n", "\r" }, StringSplitOptions.RemoveEmptyEntries);
for (var i = offset; i < raw_string.Length; i += step)
{
var row = raw_string[i].Trim().Split(',');
if (row.Length == 5)
{
gender.Add(row[0] == "Male" ? Gender.Male : Gender.Female);
height.Add(double.Parse(row[3]));
weight.Add(double.Parse(row[4]));
}
}
}
The parameter offset and step can be used to extract the data every other line:
// helloacm.com
// training set
List<Gender> train_gender = new List<Gender>();
List<double> train_height = new List<double>();
List<double> train_weight = new List<double>();
// verification
List<Gender> veri_gender = new List<Gender>();
List<double> veri_height = new List<double>();
List<double> veri_weight = new List<double>();
// read data and split into training set and verification
const string filename = @"data.csv";
ReadData(filename, train_gender, train_weight, train_height, 1, 2);
ReadData(filename, veri_gender, veri_weight, veri_height, 2, 2);
Linear Model
If we plot the weight over height, we can see there is a strong correlation between these two variables.
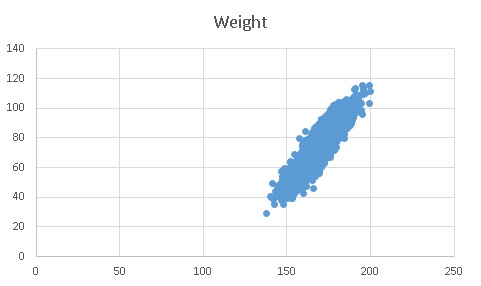
linear-model-weight-over-height
So we can re-write the above using the linear equation (in other words, a single line).
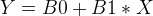 .
.
To estimate B0 and B1, we need to use two math functions, the Correl and StdDev.
Correl function
The Correl function returns a number between -1 to 1 where +1 means a perfect positive correlation between the given two variables (vector). It can be computed as:
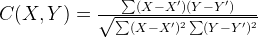
where X’ is the mean for X and Y’ is the mean for Y. To compute C, we can use the following C# method:
// helloacm.com
static double Correl(IList<double> X, IList<double> Y)
{
if (X == null || Y == null)
{
throw new ArgumentNullException();
}
if (X.Count != Y.Count)
{
throw new Exception("X.Count != Y.Count");
}
if (X.Count <= 1)
{
throw new Exception("At least 2");
}
var meanX = X.Average();
var meanY = Y.Average();
var result1 = 0.0;
var result2 = 0.0;
var result3 = 0.0;
for (var i = 0; i < X.Count; i ++)
{
result1 += (X[i] - meanX)*(Y[i] - meanY);
result2 += (X[i] - meanX)*(X[i] - meanX);
result3 += (Y[i] - meanY)*(Y[i] - meanY);
}
return result1/(Math.Sqrt(result2*result3));
}
Standard Deviation
The STD-DEV (Standard Deviation) is a measure of how widely values are dispersed from the mean. It can be computed as:
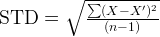
where X‘ is the mean of the sample and n is the number of the samples. The C# code to compute the STD is follows:
// helloacm.com
static double StdDev(IList<double> X)
{
if (X == null)
{
throw new ArgumentNullException();
}
if (X.Count <= 1)
{
throw new Exception("At least 2");
}
var meanX = X.Average();
var result = 0.0;
for (var i = 0; i < X.Count; i++)
{
result += (X[i] - meanX)*(X[i] - meanX);
}
return Math.Sqrt(result/(X.Count - 1));
}
Now, we can have an estimation on the B0 and B1:
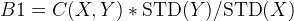
where X is the height training set and Y is the weight training set.
and
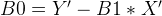
where Y’ is the mean for weight training set and X’ is the mean for the height training set.
Now, we estimate the Single model to predict the weight for all genders:
// helloacm.com
// get model
var B1 = Correl(train_height, train_weight) * StdDev(train_weight) / StdDev(train_height);
var B0 = train_weight.Average() - B1*train_height.Average();
// weight = B0 + B1 * height
List<double> pred_weight = new List<double>();
for (var i = 0; i < veri_height.Count; i ++)
{
var pred = B0 + B1*veri_height[i];
pred_weight.Add(pred);
}
And we can export the data for comparison (RMSE = 5.54)
// helloacm.com
var r = "Gender, Height, Weight, Prediction" + Environment.NewLine;
for (var i = 0; i < veri_weight.Count; i ++)
{
r += (veri_gender[i] == Gender.Male ? "Male" : "Female") + "," + veri_height[i] + "," + veri_weight[i] + "," +
pred_weight[i] + Environment.NewLine;
}
File.WriteAllText(@"prediction.csv", r);
// difference
Console.WriteLine("B1 = " + B1);
Console.WriteLine("B0 = " + B0);
Console.WriteLine("RMSE = " + RMSE(pred_weight, veri_weight));
If we plot the data, we can see the prediction model is actually a linear line model.
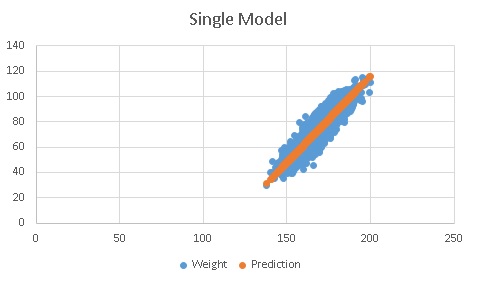
single-prediction-model
Separate Man and Woman
Can we improve the prediction model? Yes, because men and women are different in terms of weight/height correlation. If we plot data, we can easily see that:
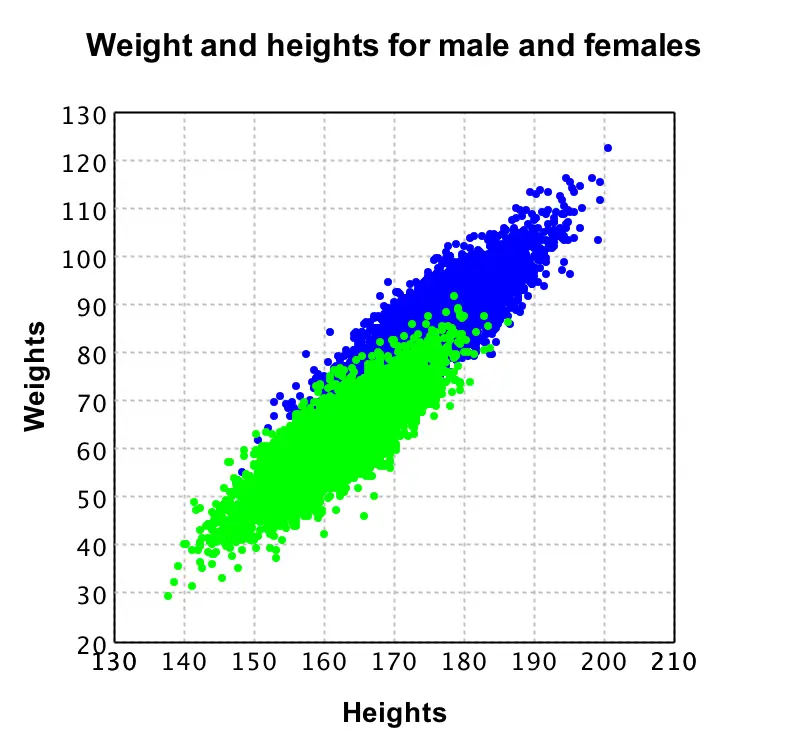
Male Female Weight/Height
So, let’s separate the data first:
// helloacm.com
private static void ReadData(string filename, IList<double> male_weight, IList<double> male_height, IList<double> female_weight, IList<double> female_height, int offset, int step)
{
var raw_string = File.ReadAllText(filename).Split(new[] { "\n", "\r" }, StringSplitOptions.RemoveEmptyEntries);
for (var i = offset; i < raw_string.Length; i += step)
{
var row = raw_string[i].Trim().Split(',');
if (row.Length == 5)
{
if (row[0] == "Male")
{
male_height.Add(double.Parse(row[3]));
male_weight.Add(double.Parse(row[4]));
}
else
{
female_height.Add(double.Parse(row[3]));
female_weight.Add(double.Parse(row[4]));
}
}
}
}
And we can read them into separate lists:
// helloacm.com
// training set
List<double> male_train_height = new List<double>();
List<double> male_train_weight = new List<double>();
List<double> female_train_height = new List<double>();
List<double> female_train_weight = new List<double>();
ReadData(filename, male_train_weight, male_train_height, female_train_weight, female_train_height, 1, 2);
Then, we get the B0 and B1 separated for male and female:
// helloacm.com
// get model for male
var male_B1 = Correl(male_train_height, male_train_weight) * StdDev(male_train_weight) / StdDev(male_train_height);
var male_B0 = male_train_weight.Average() - male_B1 * male_train_height.Average();
// get model for female
var female_B1 = Correl(female_train_height, female_train_weight) * StdDev(female_train_weight) / StdDev(female_train_height);
var female_B0 = female_train_weight.Average() - female_B1 * female_train_height.Average();
// predict using two models
// weight = B0 + B1 * height
List<double> better_pred_weight = new List<double>();
for (var i = 0; i < veri_height.Count; i++)
{
if (veri_gender[i] == Gender.Male)
{
better_pred_weight.Add(male_B0 + male_B1 * veri_height[i]);
}
else
{
better_pred_weight.Add(female_B0 + female_B1 * veri_height[i]);
}
}
And the RMSE we get using this is 4.5, which is an obvious improvement.
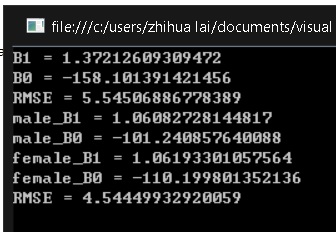
ld-results-machine-learning
Male Weight = -101.24 + 1.061 * Height
Female Weight = -110.20 + 1.062 * Height
BTW, this is called supervised learning where you have data X and output Y and you use an algorithm to learn the mapping function from the input to the output.
I am 174cm, based on the model, my weight 'should be' 82.2kg.... My actual weight is 80.0kg well this is so correct! I should let my wife know because she thinks I am overweight! Share on XUpdate: even C# is a RAD (Rapid Application Development) programming language, you are still required to write a signification amount of code, in the field of data mining, statistic analysis, machine learning (big data), there are better programming languages, such as R or Python. This post analyses the above data and gives a linear model with a few lines of code in R programming language.
–EOF (The Ultimate Computing & Technology Blog) —
2445 wordsLast Post: Gaming Adaptations for Different Platforms
Next Post: Counting Number of Set Bits for N Integers using Dynamic Programming Algorithm in Linear Time
Hey its look like there is no main method so I can’t able to execute program.
Please bundled this into single file will be very helpful.
Please send it to my email id.