There are some nice images on Tumblr. We can use Tumblr APIs to search and download images however this usually requires the registration and API keys. Another way is to crawl the HTML web pages and parse the DOM (Document Object Model), which allows us to retrieve the image URLs and their descriptions.
There is a handy Library which is called PHPQuery. It allows us to write JQuery-style PHP in the way that we write JQuery, using CSS selectors. It makes the PHP powerful in analyzing the DOM of any HTML pages.

phpquery
The following is a psudo-code that illustrates how to parse the HTML pages and grab the images.
With PHPQuery, it becomes so much easier to analyse the DOM! Share on X
require('phpQuery.php');
require('app.php');
$ip = get_ip_address();
function grab($url, $lvl = 5) {
global $ip;
if ($lvl < = 0) {
return;
}
$doc = phpQuery::newDocumentFile($url);
foreach(pq('div.TumbPostPane') as $p) {
$img = pq($p)->find('img.PhotoPostMainPhoto')->attr('src');
$desc = htmlspecialchars(trim(pq($p)->find('div.MetaPanel')->html()));
$url = pq($p)->find('a')->attr('href');
$err = '';
if (UploadPic($img, $desc, $err, $ip)) { // find pictures and save locally
echo "OK = $err \n";
} else {
echo str_replace("
", "\n", "Error = $err \n");
}
grab($url, $lvl - 1); // recursive download
}
}
grab("https://uploadbeta.com", 1);
With little modification, you can let the script crawling several thousands of pictures within a few minutes. All images are saved to local databases in the VPS server. The pictures can be seen at: uploadbeta.com
It is better to set a time interval between page crawling otherwise, the IP address may be blocked.
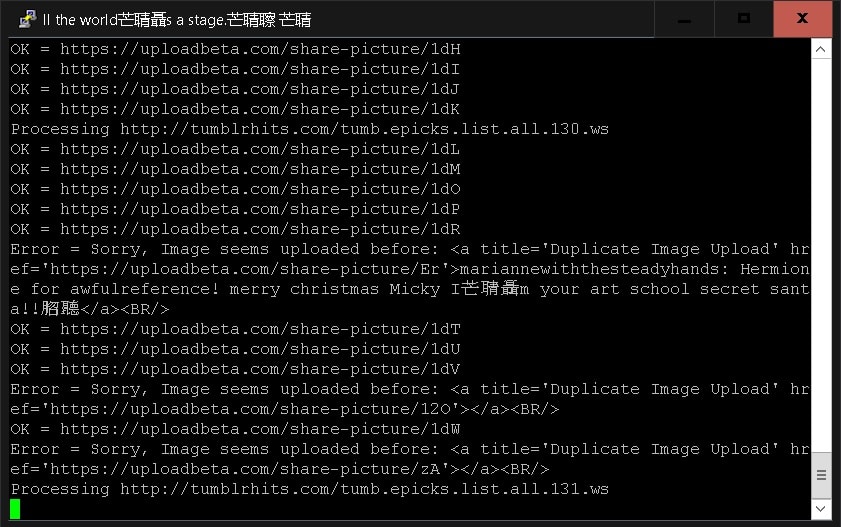
Image Crawling
PS, the Image Upload website supports a few APIs for various purposes subject to fair use policy: https://uploadbeta.com/picture-gallery/faq.php#api
–EOF (The Ultimate Computing & Technology Blog) —
491 wordsLast Post: Shell Coding Exercise - Word Frequency
Next Post: C++ Range Sum Query on Immutable Array via Prefix Sum
what about self-closing tag and the unclosed ?
doesn’t matter, the PHPQuery recognizes self-closing tag.
unclosed tag is not a valid HTML, which produces unexpected (unstable) results.
It seems that WP has removed the tag I mentioned in my comment above.
There are many html documents use <br> to represent as a soft break,not the slash one: <br/>. And <p>, in H5, it is valid.
So they are not strict, well-formed XML. Many DOM parsers cannot handle them well.