The problem is from codeforces: http://www.codeforces.com/problemset/problem/125/B
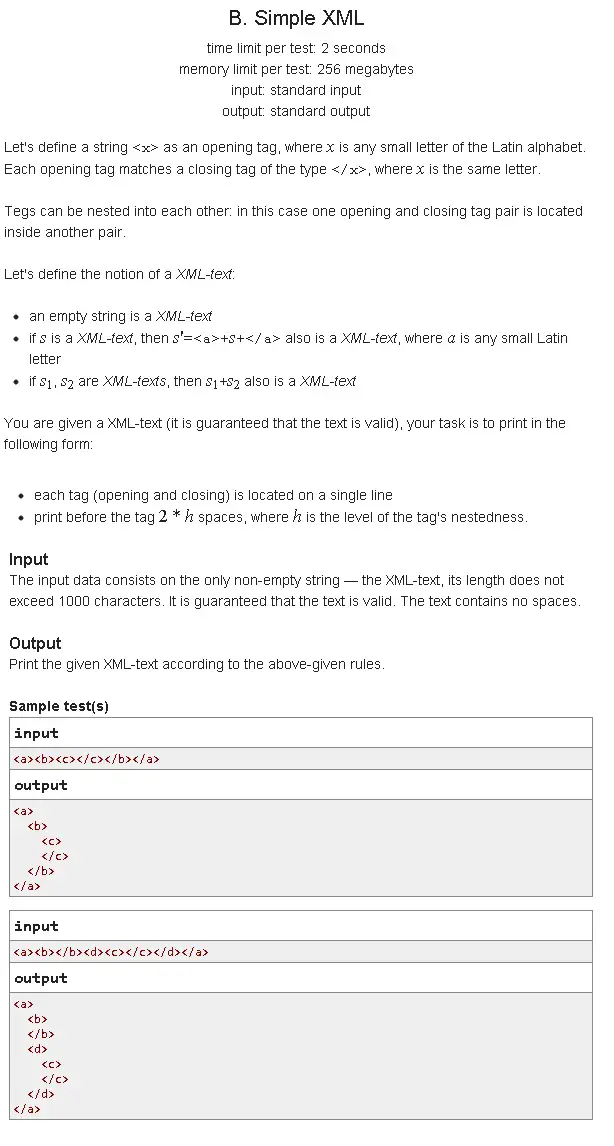

The given input has no format errors, which makes it easy to solve because you don’t have to consider unregular situations such as tags are not nested correctly. I think most of the algorithms have to consider two cases, the starting tag “<a>” and ending tag “</a>”. For each starting tag, you increase the lvl by one, and for each ending tag, you decrease the level by one.
To print 2 * h number of spaces, in Python, you can use the built-in operations “*”, for example,
print "abc" * 4
gives the output abcabcabcabc
The straightforward implementation in Python is given below.
#!/usr/bin/env python
from sys import *
s = stdin.readline()
i = 0
j = len(s)
lvl = 0
while i < j:
c = s[i]
if c == '<':
if s[i + 1] == '/':
i += 1
k = i + 1
while s[k] != '>':
k += 1
tag = s[i + 1: k]
lvl -= 2
print " " * lvl + "
The short description of the algorithm shown above is analyse each tag “<a>” or “</a>” respectively. It is noted that the alternative to read from stdin other than raw_input() is using sys.stdin.readline(), as shown in the code.
However, using Regular expressions re in Python gives a much shorter code.
import re
l=0
for q in re.findall('.*?>',raw_input()):l-=q<'<0';print" "*l*2+q;l+=q>'<0'
The problem statements says that there is no space in the given input, therefore, you might also split the input by the delimiter “><“:
text = raw_input()[1:-1].split("><")
s = 0
for tag in text:
if tag[0] == '/':
s -= 1
tag = tag[1:]
print "%s</%s>"% (' ' * s, tag)
else:
print "%s<%s>" % (' ' * s, tag)
s += 1
It is interesting to find that using Python, you can write many accepted solutions that look differently, and in just a few lines of code.
–EOF (The Ultimate Computing & Technology Blog) —
Last Post: Codeforces: A. Theatre Square
Next Post: Command Line Arguments in Python Script